![$\textstyle\parbox{70mm}{
Zutaten:
\begin{itemize}
\item Universum $U$\space ...
...e Hashtabelle
\item Hashfunktion $h:U \rightarrow [0..m-1]$\\ \end{itemize} }$](img187.gif)
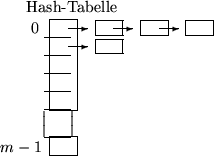
Problemstellung: Gegeben sei eine Menge M von Elementen, von denen jedes durch
einen Schlüssel k aus der Menge K bezeichnet sei. Die Problemstellung ist nicht neu:
Wie muß die Speicherung der Elemente aus M organisiert werden, damit jedes anhand eines
Schlüssels möglich schnell lokalisiert werden kann? Gesucht ist also eine Abbildung ![]() von der Menge aller Schlüssel in Adressraum T der Maschine. Hierbei soll
jedoch eine bisher nicht beachtete Schwierigkeit berücksichtigt werden: Die Menge K der
möglischen Schlüsselwerte ist wesentlisch größer als der Adreßraum. Folglich kann die
Abbildung h nicht injektiv sein, es gibt Schlüssel k1, k2, .. mit
von der Menge aller Schlüssel in Adressraum T der Maschine. Hierbei soll
jedoch eine bisher nicht beachtete Schwierigkeit berücksichtigt werden: Die Menge K der
möglischen Schlüsselwerte ist wesentlisch größer als der Adreßraum. Folglich kann die
Abbildung h nicht injektiv sein, es gibt Schlüssel k1, k2, .. mit ![]() . Wir werden sehen, daß aufgrund dieses Umstandes die Speicherstelle eines Elements mit
Schlüssel k von einem anderen Element mit einem anderen Schlüssel l besetzt sein kann
(Kollision).
. Wir werden sehen, daß aufgrund dieses Umstandes die Speicherstelle eines Elements mit
Schlüssel k von einem anderen Element mit einem anderen Schlüssel l besetzt sein kann
(Kollision).
Zwei Methoden zur Kollisionsauflösung: